Ankündigung: Neufassung der Namenskomponenten
Notwendigkeit und Zielsetzung der Neufassung
Angekündigte Änderungen für die nächste Version von OSCI XMeld: In dem OSCI XMeld Projekt wurde entschieden, die Datentypen für den Namen natürlicher Personen zu ändern.
Die geplanten Änderungen werden im folgenden beschrieben. Sie sind in der vorliegenden Spezifikation nur als Ankündigung zu verstehen. In allen Datentypen und Nachrichten, die in dieser Spezifikation beschrieben werden, wird noch auf die seit OSCI XMeld 1.0 bekannten Namenskomponenten Bezug genommen die in der Spezifikation beschrieben sind. Bis zur nächsten Version von OSCI XMeld sollen aber im gesamten Fachmodell von OSCI XMeld und in den Schemata die alten Namenskomponenten durch die im Folgenden dargestellten ersetzt werden.
Die folgenden Aspekte haben zu der Entscheidung geführt, trotz des damit verbundenen Aufwandes die zentrale Datenstruktur NameNatürlichePerson und die damit unmittelbar zusammenhängenden Datenstrukturen neu zu modellieren:
Stärkere Ausdrucksmächtigkeit
In den einschlägigen Rechtsgrundlagen zur Übermittlung von Meldedaten werden bezüglich der Übermittlung von Namen oder Namenskomponenten häufig Einschränkungen vorgenommen. In bestimmten Situationen wird beispielsweise festgelegt, dass nur der aktuelle Familienname und der aktuelle Vorname übermittelt werden dürfen. Dementsprechend dürften in diesem Beispiel die früheren Namen oder der Geburtsname des Betroffenen nicht übermittelt werden.
Mit der bisher vorhandenen Namensstruktur kann eine solche Einschränkung lediglich verbal gefordert werden. Wir verfügen nicht über die Möglichkeit, die Einhaltung dieser Einschränkung mit den Mitteln von XML Schema auszudrücken. Hierfür wäre ein Sprachkonstrukt erforderlich, welches ausdrücken würde: „In dem übermittelten Element nachname muss dass Attribut rolle den Wert FN besitzen.“ Dies ist mit den Mitteln von XML Schema nicht möglich. Validierende Parser würden nicht prüfen können, ob diese Bedingung eingehalten wird.
Ein Ziel der Neufassung bestand darin, dass zukünftig mit den Mitteln von XML Schema präziser ausgedrückt werden kann, welche Namenskomponenten in einer Nachricht zugelassen sind.
Reduktion der Komplexität
Die bisher vorhandene Namensstruktur und ihre Komponenten (Vorname, Nachame) waren aus Sicht der Implementierung komplexer als andere Datentypen, da einige Randbedingungen zu beachten waren, die nicht mit den Mitteln von XML Schema ausgedrückt werden können und daher in der programmiertechnischen Umsetzung als zusätzliche Anwendungslogik notwendig waren. Zu diesen Rahmenbedingungen gehören unter anderem:
In einem Namen darf es zwar mehrere Nachnamen geben, aber stets maximal eines der Elemente darf in einer der rollen „Geburtsname“ oder „Ehename“ oder „Lebenspartnerschaftsname“ oder „(aktueller) Familienname“ auftreten.
Es darf mehrere Vornamen geben, aber diese müssen korrekt durchnummeriert sein. Es darf keine zwei Elemente mit der gleichen rolle geben, die die gleiche laufendeNr haben.
Darüber hinaus gab es keine „einfache“ Methode um festzustellen, ob z. B. ein aktueller Familiennamen als Bestandteil eines Namens übermittelt worden ist. Hierfür war die Liste aller Nachnamen darufhin zu überprüfen, ob einer (und nur einer) die rolle „FN“ besaß.
Ein Ziel der Neufassung bestand darin, die mit dem Namen verbundenen Datenstrukturen in ihrer Komplexität zu reduzieren und damit „einfachere“ Implementierungen zu erlauben – auch wenn es aus der Sicht der OSCI XMeld-Modellierung sicherlich nicht immer eindeutig zu beurteilen ist, wie sich die Situation aus Sicht der Entwickler darstellt.
Stärkere Nähe zu DSMeld
In der bisherigen Datenstruktur nameNatuerlichePerson konnte auf Grund des Rollenkonzeptes nur in allgemeiner Form angegeben werden, dass ein Name aus mehrere Nachnamen bestehen kann, die in verschiedenen Rollen auftreten können. Die möglichen Rollen sind im DSMeld definiert.
Ein Ziel der Neufassung bestand darin, innerhalb der Struktur nameNatuerlichePerson die Elemente einzufügen, die einen unmittelbaren Bezug zum MRRG und zum DSMeld haben (zum Beispiel ehename, geburtsname und so weiter.
Wesentliche Unterschiede zwischen bisheriger und neuer Modellierung
Um die in Abschnitt namens Notwendigkeit und Zielsetzung der Neufassung dargestellten Ziele erreichen zu können, wurden folgende wesentliche Veränderungen in den hier betrachteten Datenstrukturen vorgenommen:
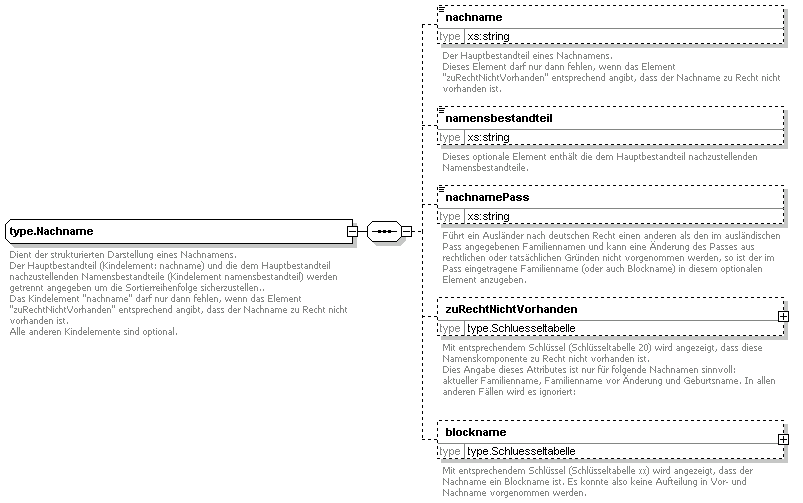
Datentyp nachname
Der Datentyp type.Nachname dient der strukturierten Darstellung von Nachnamen gemäß § 2 Abs. 1 Nr. 1 und Nr. 2 MRRG. Durch die Neufassung ergeben sich folgende Unterschiede zur Version 1.2:
Das Rollenattribut entfällt. Familienname, Geburtsname und alle anderen Nachnamen werden in unterschiedlichen Elementen dargestellt (bisher: in einem wiederholbaren Element mit unterschiedlichen Rollen).
Das Attribut nachnameOriginlschreibweise entfällt.
Das optionale Attribut blockname ist neu. Es informiert darüber, dass der enthaltene String ein Blockname ist (er enthält Vor- und Nachnamen, eine Aufteilung war bei der Erfassung der Daten nicht möglich).
Das Attribut nachnamePass ist neu. Es enthält die Schreibweise des Nachnamens im Pass, die sich von der Schreibweise nach deutschem Recht unterscheidet.
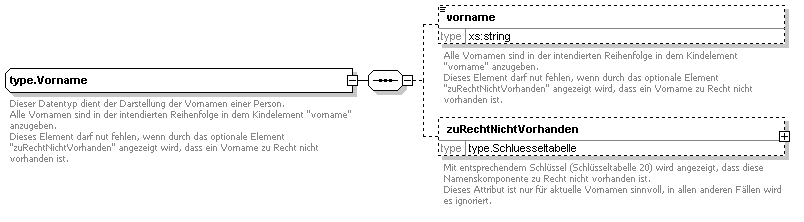
Vorname
Der Datentyp type.Vorname dient gemäß § 2 Abs. 1 Nr. 3 der Darstellung der Vornamen einer Person. Durch die Neufassung ergeben sich folgende Unterschiede zur Version 1.2:
Das Attribut rolle entfällt.
Aktuelle und frühere Vornamen werden in unterschiedlichen Elementen dargestellt.
Alle Vornamen werden in einem String statt in wiederholbaren Feldern gespeichert. (Bisher: je ein Vorname in einem wiederholbaren Element).
Diese Darstellung entspricht den Vorgaben des DSMeld und, soweit uns dies bekannt ist, auch der Praxis in den meisten EWO-Verfahren.
Daher entfällt auch das Attribut laufendeNr.
Der Rufname der Person wird in einem eigenen Element gespeichert.
Das Attribut vornameOriginalSchreibweise entfällt.
Doktorgrad
Der Datentyp type.doktorgrad dient gemäß § 2 Abs. 1 Nr. 4 der Darstellung der Doktorgrade, die in Pässe eingetragen werden dürfen. Durch die Neufassung ergeben sich folgende Unterschiede zur Version 1.2:
Alle Doktorgrade werden in einem String statt in einem wiederholbaren Element gespeichert.
Diese Darstellung entspricht den Vorgaben des DSMeld und, soweit uns dies bekannt ist, auch der Praxis in den meisten EWO-Verfahren.
Da es sich bei diesem Datentyp lediglich um einen String handelt (ggfs. weiter eingeschränkt durch zulässige Zeichenmuster), wird er zukünftig in xmeld-basistypen.xsd definiert.
Weitere Namen
Der Datentyp type.WeitererName dient der Darstellung weiterer Namen gemäß § 2 Abs. 1 Nr. 5 MRRG. Durch die Neufassung ergeben sich folgende Unterschiede zur Version 1.2:
Ordensnamen und Künstlernamen werden in unterschiedlich benannten Elementen dargestellt. (Bisher: in einem wiederholbaren Element).
Daher entfällt das Attribut rolle.
Da es sich bei diesem Datentyp lediglich um einen String handelt (ggfs. weiter eingeschränkt durch zulässige Zeichenmuster), wird er zukünftig in xmeld-basistypen.xsd definiert.
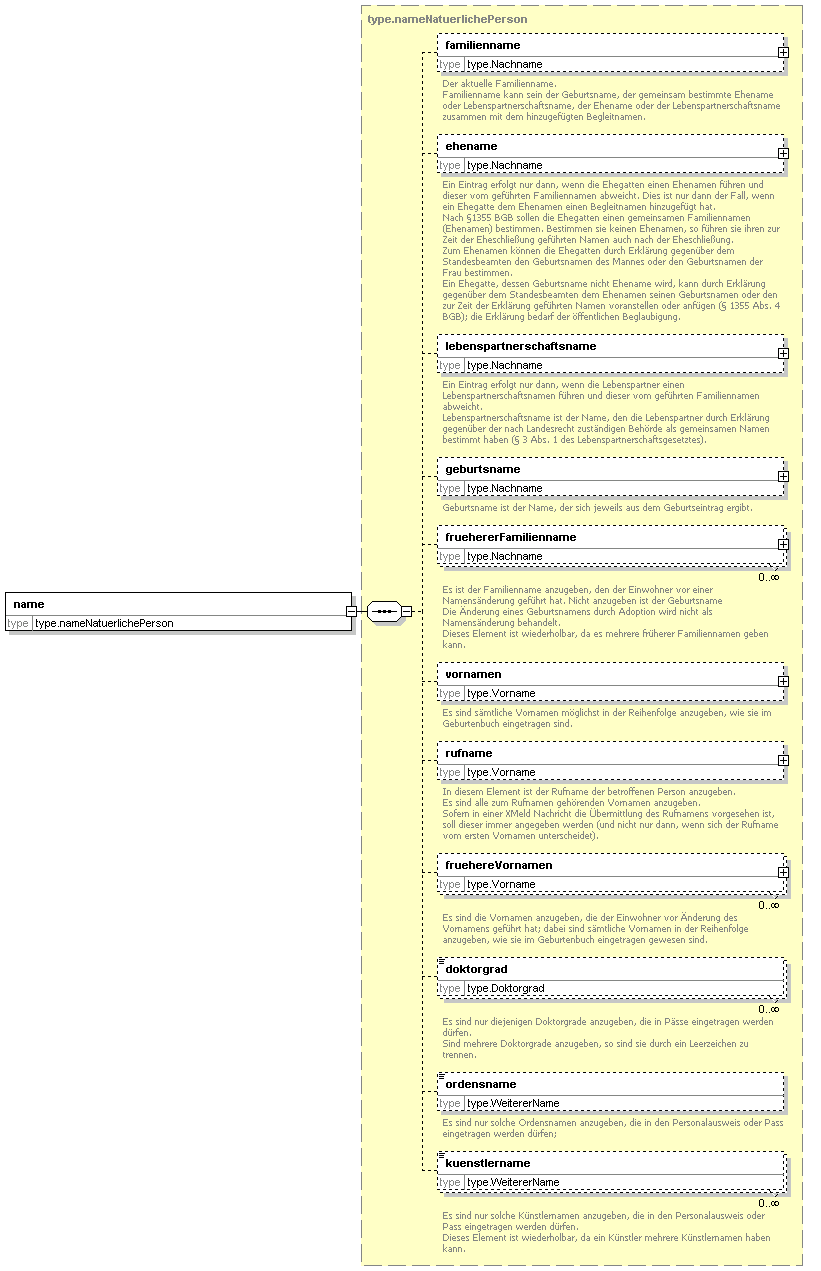
Der Name natürlicher Personen
Dieser Datentyp aggregiert die verschiedenen Namenskomponenten. Da es ein Aggregat ist, gibt es keine unmittelbare Entsprechung im DSMeld. Bisher enthielt dieser Datentyp wiederholbare Elemente für Nachnamen, Vornamen, Titel und weitere Namen. Um welchen Nachnamen es ging, war anhand des Attributes rolle erkennbar. Analoge Regelungen galten für Vornamen und weitere Namen.
Zukünftig aggregiert der Datentyp type.NameNatuerlichePerson folgende Elemente:
familienname, ehename, lebenspartnerschaftsname, geburtsname und fruehererFamilienname (alle vom Typ type.nachname).
vorname, rufname und fruehererVornname (alle vom Typ type.vorname).
doktorgrad vom Typ type.doktorgrad.
ordensname und kuenstlername vom Typ type.weitererName.
Beispiele für die neuen Namenskomponenten
Die folgenden Beispiele sollen die Nutzung der neuen Namenskomponenten erläutern.
Beispiel 1. Familienname und Vorname
Darstellung des Namens von Frau Mustermann, Gabriele.
<name>
<familienname>
<nachname>Mustermann</nachname>
</familienname>
<vornamen>
<vorname>Gabriele</vorname>
</vornamen>
<rufname>
<vorname>Gabriele</vorname>
</rufname>
</name>
Beispiel 2. Familienname mit Namensbestandteil
Darstellung des Namens von Frau von Mustermann, Gabriele. Durch die Aufteilung des Familiennamens in den Hauptbestandteil und den nachzustellenden Namensbestandteil wird sichergestellt, dass dieser Name in einer alphanummerischen Sortierung unter „Mustermann“ einsortiert wird.
<name>
<familienname>
<nachname>Mustermann</nachname>
<namensbestandteil>von</namensbestandteil>
</familienname>
<vornamen>
<vorname>Gabriele</vorname>
</vornamen>
<rufname>
<vorname>Gabriele</vorname>
</rufname>
</name>
Beispiel 3. Familien- und Geburtsname, Rufname abweichend von den Vornamen
Im folgenden Beispiel wird neben dem aktuellen Familiennamen auch der Geburtsname übermittelt. Außerdem ist der Rufname abweichend von den Vornamen. Es werden mehrere Vornamen in einem String angegeben. Dargestellt wird der Name von Frau von Mustermann, Gesine Charlotte, geborene Zumbusch, Rufname Sissi.
<name>
<familienname>
<nachname>Mustermann</nachname>
<namensbestandteil>von</namensbestandteil>
</familienname>
<geburtsname>
<nachname>Zumbusch</nachname>
</geburtsname>
<vornamen>
<vorname>Gesine Charlotte</vorname>
</vornamen>
<rufname>
<vorname>Sissi</vorname>
</rufname>
</name>
Beispiel 4. Blockname
Das folgende Beispiel verdeutlicht anhand des Namens von Herrn KHALED RAMADAN AHMED IBRAHIM AKB ELABAB (aus Ägypten) die Nutzung des Blocknamens. Eine Aufteilung des Namens in Vor- und Nachnamen konnte nicht vorgenommen werden.
<name>
<familienname>
<nachname>KHALED RAMADAN AHMED IBRAHIM AKB ELABAB</nachname>
<blockname>
<tabelle>http://www.osci.de/xmeld13/spezifikation#schluesseltabellexx</tabelle>
<schluessel>1</schluessel>
</blockname>
</familienname>
<vornamen>
<zuRechtNichtVorhanden>
<tabelle>http://www.osci.de/smeld13/spezifikation#schluesseltabelle20</tabelle>
<schluessel>1</schluessel>
</zuRechtNichtVorhanden>
</vornamen>
</name>